



The next tutorial is a practical guide, after reading the next steps you will not become a Senior Semantic Versioning Full Stack Release Manager, but you will have a small idea of what is going on behind the synced semantic versioning concept.
What is Semantic Versioning?
SEMVER is a solution proposal to the very known problem called "dependency hell". The main purpose is to organise the version number into a hierarchical order that is given by a semantic meaning.
According to the official documentation of SEMVER, you can set semantic information into the version number just by following the next hierarchical order:
Given a version number MAJOR.MINOR.PATCH, increment the:
MAJOR version when you make incompatible API changes, MINOR version when you add functionality in a backwards compatible manner, and PATCH version when you make backwards compatible bug fixes. Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
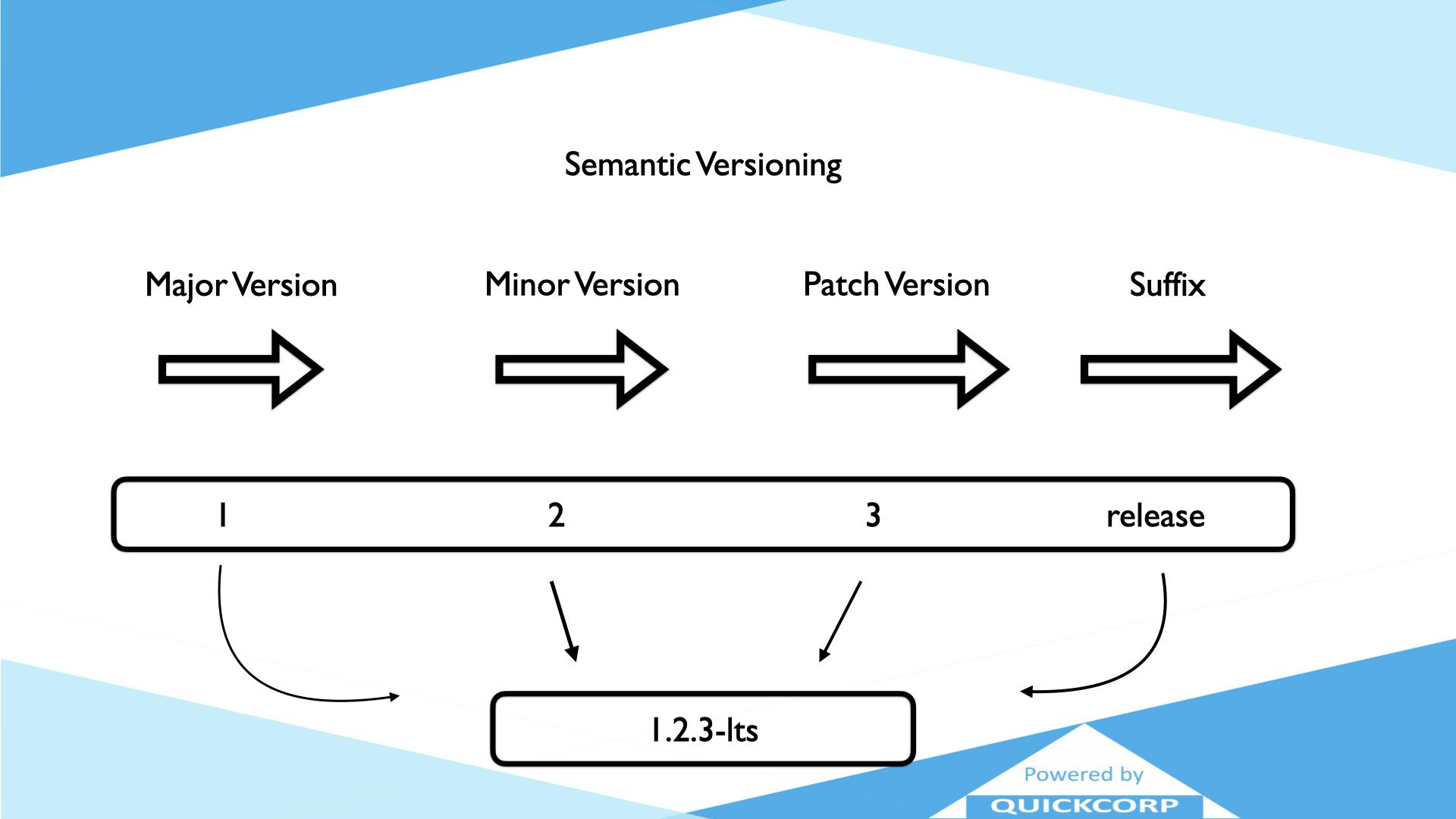
In the above example, the version number 1.2.3-lts can be easily interpreted as:
A Major number 1 with a minor number 2 and a patch number 3 and lts is probably meaning that this version is the latest stable with that given number
What is Synced Semantic Versioning
Well, you probably already know and understand very well what is all about semantic versioning, and you have applied the concept to your Github repo, you probably are using a git tag to name a version using the concept of semantic versioning in the best way you can do it manually, right? But it is not easy to maintain a good tracking of the version number in your repo if you are not able to put the same number in your npm, or docker image at the same time because you simply forgot it to do this time. So now, you have a 1.2.3-lts number in your git repo, and you have a 1.2.29-current number in your npm repo. Both are well enough semantic, but they are not synced. But no worries, this is becoming even worse! When your PO is coming to you with a new big requirement that needs to be tested but not published yet, so you make a new branch named 1.2.3-newfeature and this version is totally different to the initial 1.2.3-lts that needs to be published. How can you really know what is actually running in production stage?
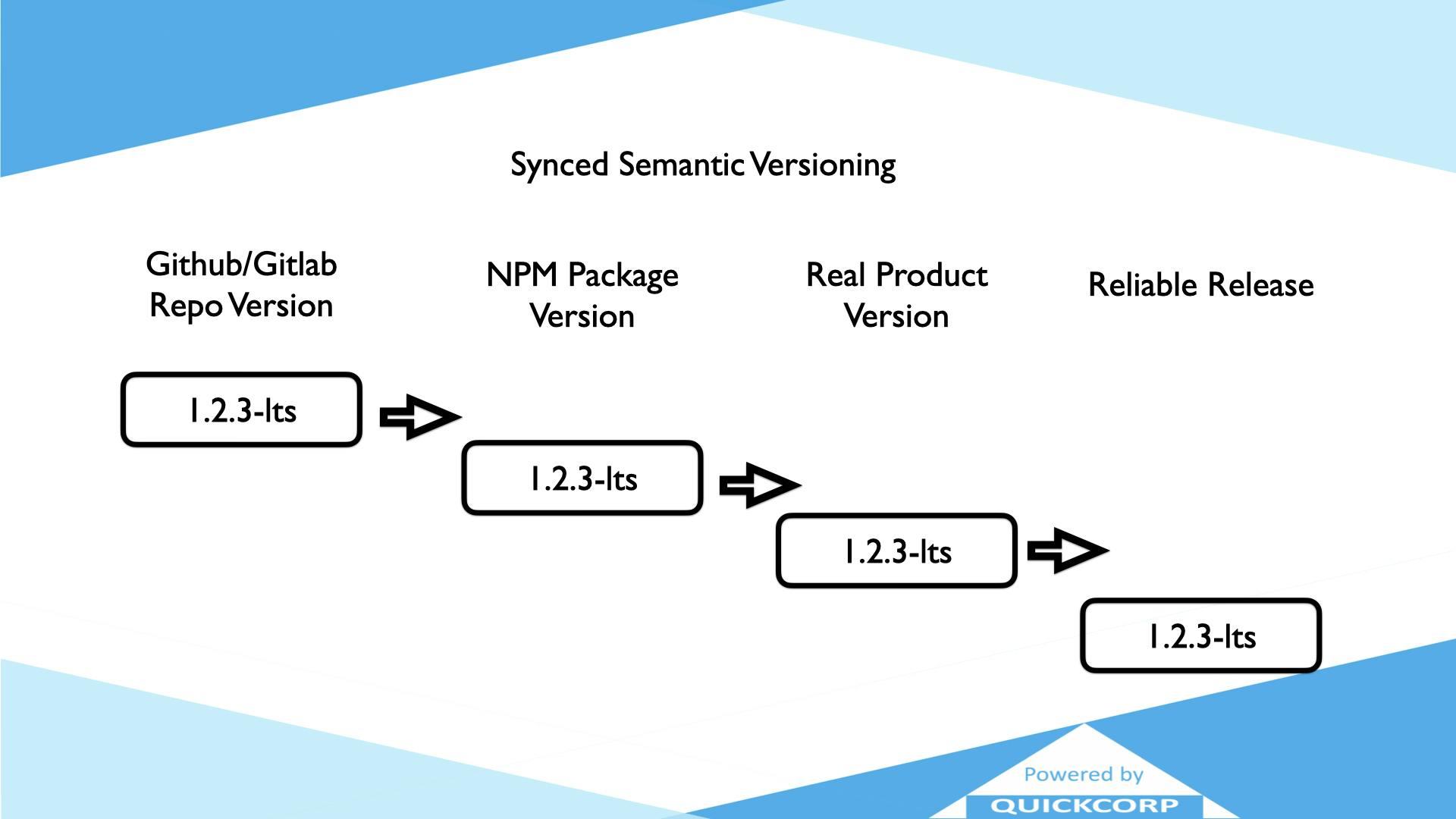
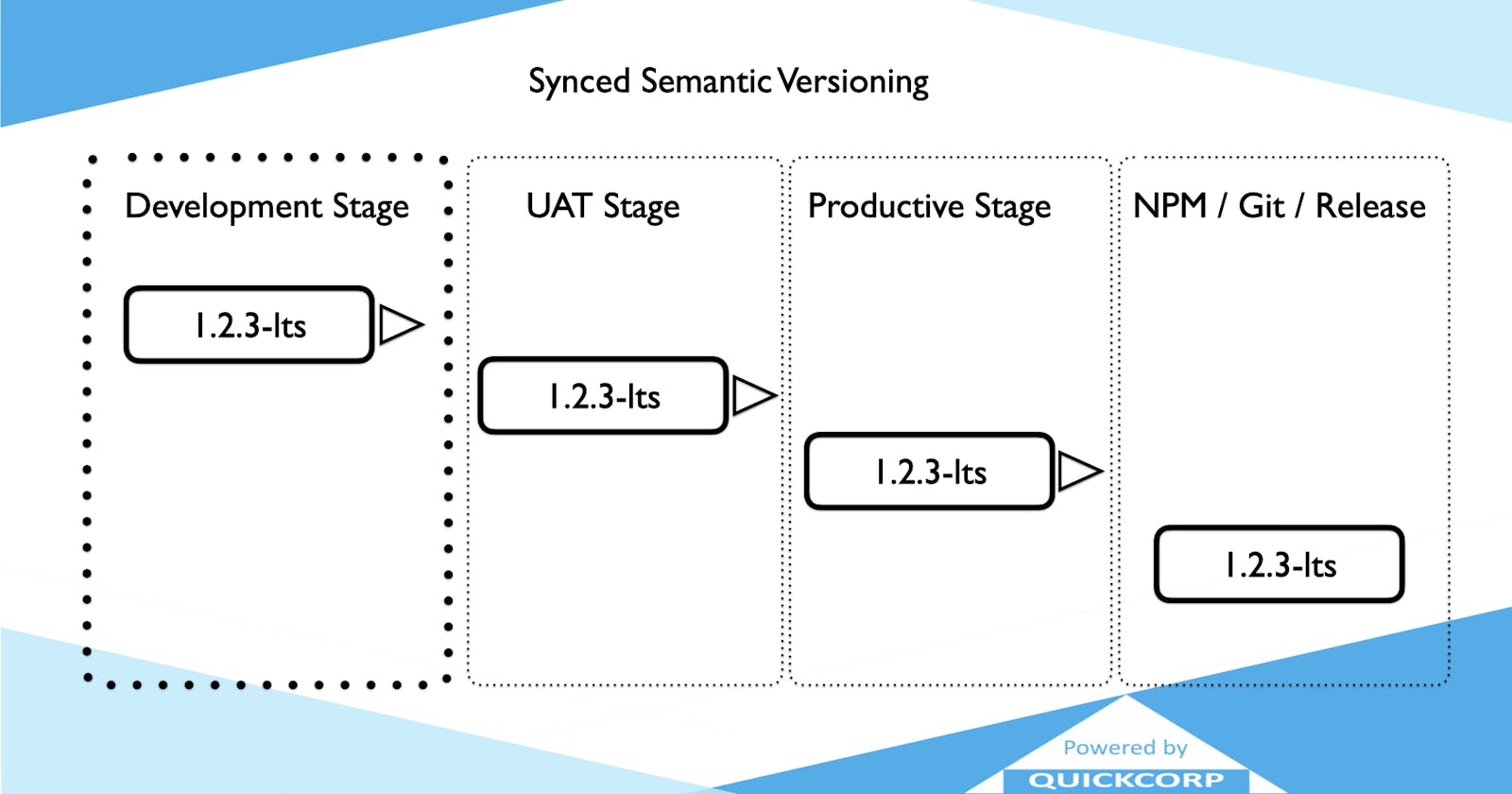
The first thing you need to ensure is that the version number in your repo is the same version number in your npm package, and it is the same version number that your PO is expecting to be running in production.
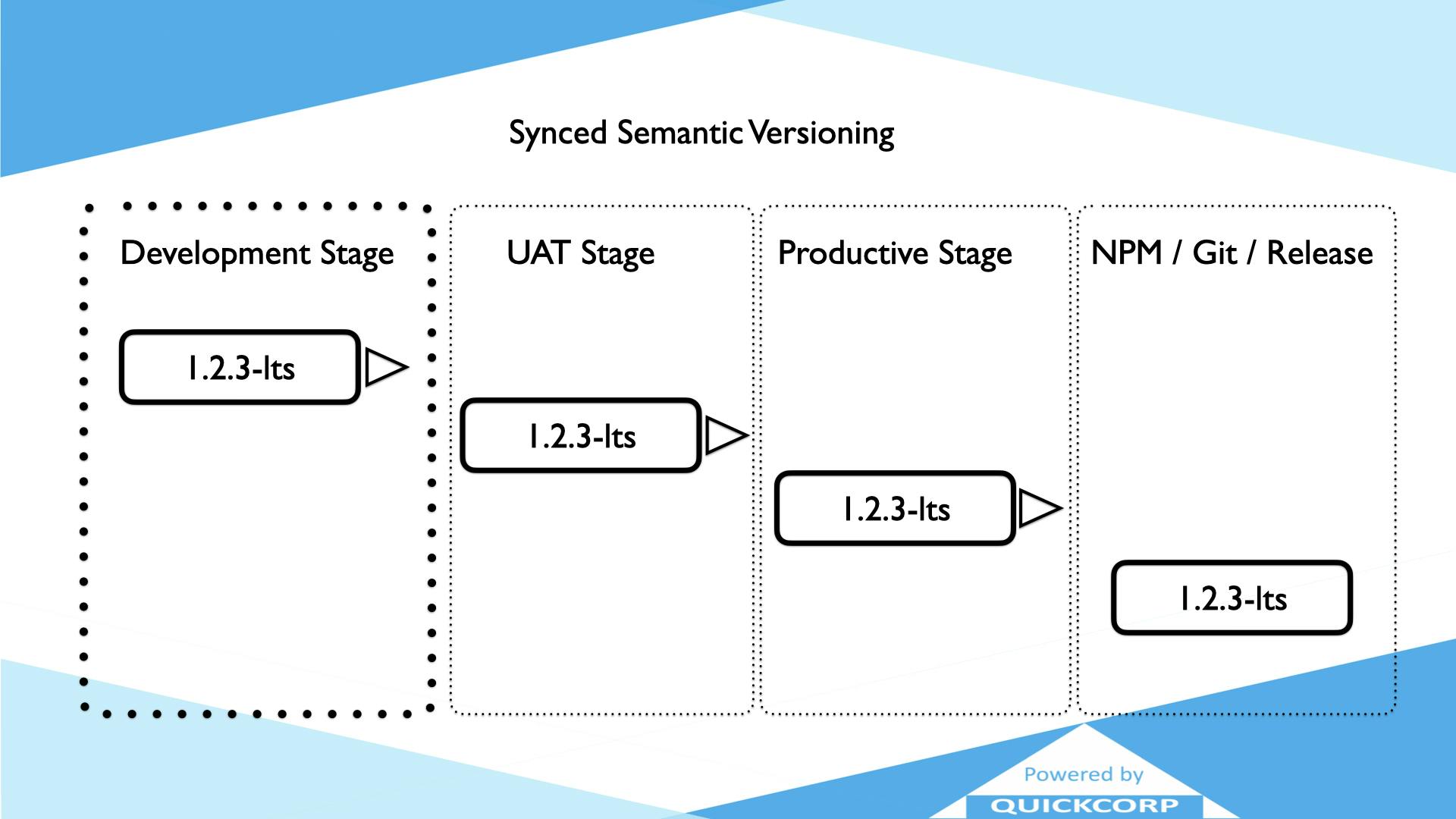
Then you have to ensure that the version of UAT is very known as different from the DEV stage version, and the PROD stage version is currently running in the right pipeline.

If you are using the master branch (keep an eye, Github is about to change this branch name soon!), I gonna give you some tips to keep accuracy and reliability in your release process:
Step one. Sync the repo version number with your current NPM package version
> qcobjects v-sync
The above command is your best friend. It will look into your git repo looking for version tags, and then it will create a file named VERSION into your repo (don't need to add this file to .gitignore). The content of the VERSION file is the current version number of your code. This file will be used later to sync the version with git and npm.
Step two. Keep the version number updated
To keep the version number up-to-date you can use the semantic versioning commands of QCObjects CLI Tool:
To give you an example, if you want to add a new patch, just make some changes in your current branch and then use the v-patch command.
> qcobjects v-patch -m "why is this patch so good" --git --npm
The same is for a minor version:
> qcobjects v-minor -m "pretty sure these minor changes are not breaking anything" --git --npm
And for a major version:
> qcobjects v-major -m "wow, this is real, finally a new release candidate!" --git --npm
Step three. Use a pipeline to automatically publish your changes to NPM.
For this step, I highly recommend you to read this
Step four. Automate your test running process.
I don't know if you are familiar with the scripts property of the package.json file, if you aren't, just read this to understand first, and when you are ready, add this to the scripts property:
"scripts": {
"test": "jasmine",
"sync": "git add . && git commit -am ",
"preversion": "npm i --upgrade && npm test",
"postversion": "git push && git push --tags && npm publish",
"start": "node app.js"
},
NOTE: The above settings are recommended to be used when you develop apps using qcobjects create --pwa myappcommand.
Good to know you've read to this point!
Happy coding!